对比分析之前,先看看下面这个表,技术一目了然。
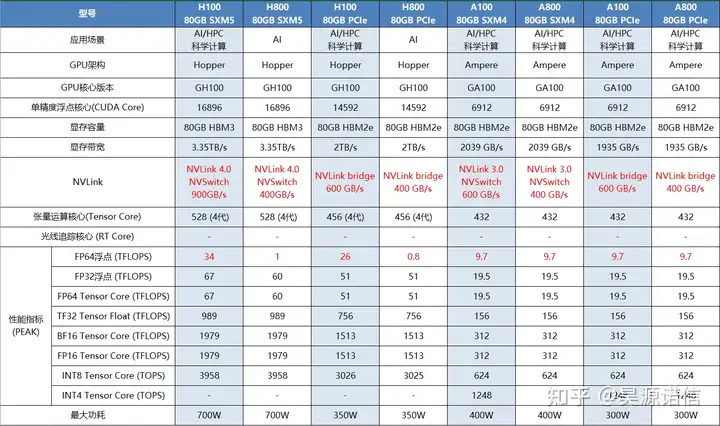
上面几个显卡型号,其实可以归为2类,一类是A100和H100,另一类是H800和H100,800系列作为中国特供版,基本上和同一代100系列的类似,只有个别参数差异,所以我们首先来看看A100和H100的差异。
A100 VS H100
1.Hopper架构升级
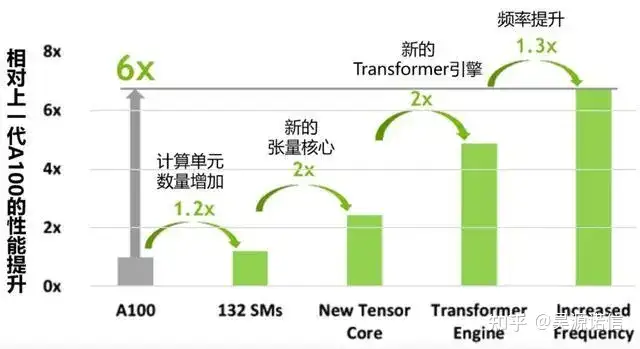
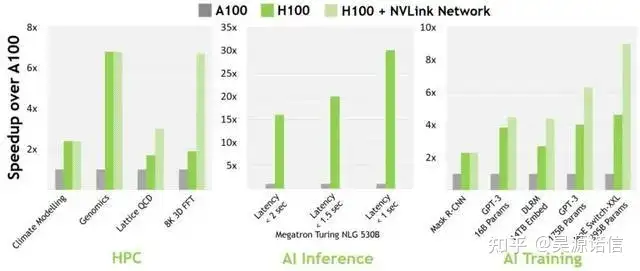
基于Hopper架构的H100,张量核心GPU已经是第九代数据中心GPU了,相比上一代安培架构的A100 GPU,Hopper架构明显强悍了很多,不仅晶体管数量有明显提升,制作工艺也从7纳米提升到4纳米,为大规模AI和HPC提供了一个数量级的性能飞跃,细节看下图。
2.NVLink Switch 系统升级
为了加快业务速度,百亿亿次级 HPC和万亿参数的 AI 模型需要服务器集群中每个GPU之间高速、无缝的通信,以实现大规模加速。
第四代 NLVink 是一种纵向扩展互联技术,当与新的外部 NVLlink 交换机结合使用时,NVLink Switch 系统现在可以跨多个服务器以每个 GPU 900 GB/s 的双向带宽扩展多 GPU IO,比 PCIe 5.0的带宽高7倍。NVLINK Switch系统支持多达256个相互连接的H100组成的集群,且带宽比Ampere架构上的InfiniBard HDR高9倍。
第三代NVSwitch技术包括驻扎在节点内部和外部的交换机,用于连接服务器、集群和数据中心环境中的多个GPU。
节点内的每个NVSwitch提供64个第四代NVLink链接端口,以加速多GPU连接。交换机的总吞吐量从上一代的7.2 Tbits/秒增加到13.6 Tbits/秒。新的第三代NVSwitch技术还为多播和NVIDIA SHARP网内还原的集体操作提供了硬件加速。
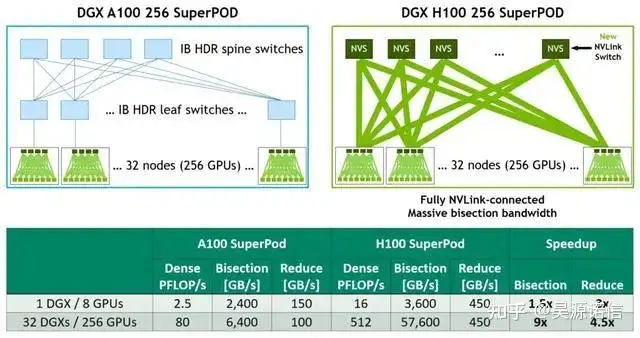
新的NVLink互连和基于第三代NVSwitch技术的新的二级NVLink Switches引入了地址空间隔离和保护,使多达32个节点或256个GPU能够通过NVLink以2:1的锥形树状拓扑连接起来。
总结一下,相比A100,H100更受欢迎,因为缓存延迟更低和计算效率更高。效率提升3倍的情况下,成本只有只有(1.5-2倍)。从技术细节来说,比起A100,H100在16位推理速度大约快3.5倍,16位训练速度大约快2.3倍。
H800 VS H100
作为H100的替代品,中国特供版H800,PCIe版本SXM版本都是在双精度(FP64)和nvlink传输速率的削减,其他其他参数和H100都是一模一样的。
FP64上的削弱主要影响的是H800在科学计算,流体计算,有限元分析等超算领域的应用,深度学习等应用主要看单精度的浮点性能,大部分场景下性能不受影响。而受到影响较大的还是NVlink上的削减,但是因为架构上的升级,虽然比不上同为Hopper架构的H100,但是比ampere架构的A800还是要强上不少的。
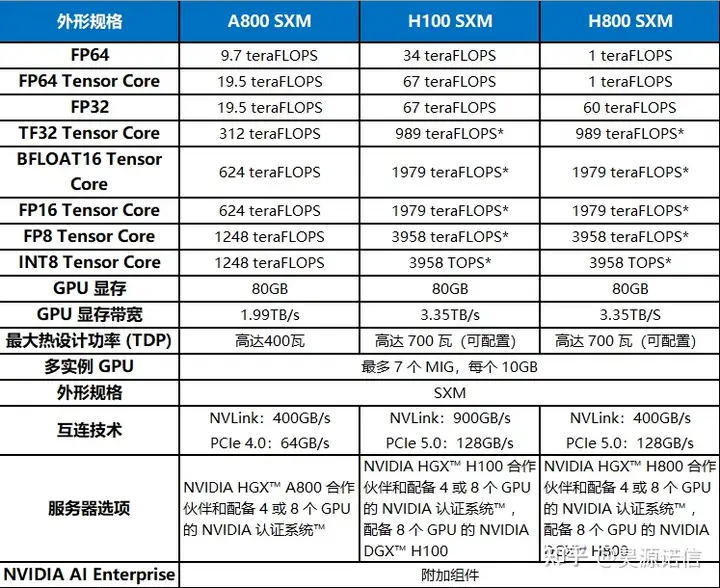
所以其实H800和H100的性能差距并没有大家想象的那么夸张,就算是削弱了FP64与NVlink传输速率,性能依旧够用,最关键的是,它合法呀(禁售,质保等问题就不在此细说了)!所以如果不是应用于超算的话也没必要冒着风险去选择H100。
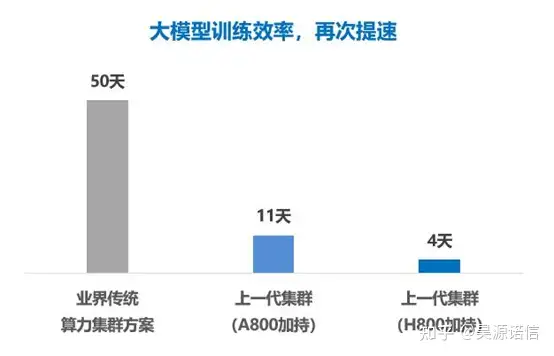
H800-GPU 可为大模型训练、自动驾驶,深度学习等提供高性能、高带宽和低延迟的集群算例。根据腾讯云新一代集群的实测数据显示,在面对万亿参数的 AI 大模型训练时,之前需要时间为 11 天,而在 H800 的加持下,新一代集群,训练时间可缩短至 4 天,证明了最新代 H800 比 A800 的高强悍性,有更高的性能,在任务处理上以最快速度处理,进一步证明了,H800 在大模型训练领域有充分的地位以及能力。
供应链方面,目前NVIDIA也是优先推H800,昨天又有消息放出称米国又对中东开始禁售H100/A100加速卡:怕专卖给中国,所以各位看官如果真有需求,还是建议选H800吧,近期会到一批H800 SXM整机,有需求的欢迎来撩~