文章目录[隐藏]
Dify与RAGFlow结合部署本地知识库并提升检索准确率的详细教程及原理分析:
一、环境准备与部署架构
硬件要求:
-
CPU≥4核(推荐支持AVX指令集) -
内存≥16GB -
磁盘≥50GB(用于存储向量索引) -
GPU非必需但可加速处理(推荐NVIDIA T4以上)
软件架构:
用户端 → Dify应用层(工作流编排) → RAGFlow引擎(文档解析/检索) → 本地LLM(Ollama等)
该架构通过API接口实现Dify与RAGFlow的解耦部署,既保证文档处理的专业性,又保持应用开发的灵活性。
二、部署步骤详解
1. RAGFlow部署(文档处理层)
# 克隆仓库并启动容器(需预先安装Docker)
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/deploy/docker
docker-compose up -d
关键配置:
-
修改 docker-compose.yml中MINIO_ROOT_PASSWORD(对象存储密钥) -
调整 elasticsearch内存分配至8GB以上
2. Dify部署(应用开发层)
# 修改环境变量(关键步骤)
vim dify-main/docker/.env
# 启用自定义模型并配置Ollama
CUSTOM_MODEL_ENABLED=true
OLLAMA_API_BASE_URL=http://[本机IP]:11434
部署命令:
cd dify-main/docker
docker compose -p dify_docker up -d
该配置实现本地模型调用,避免云端API延迟。
三、系统整合与配置
1. API对接流程
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
http://[IP]:9380 |
|
|
|
|
|
|
|
|
特别注意:需在RAGFlow中预先完成以下处理:
-
PDF文档启用"深度布局解析"模式 -
Excel表格选择"单元格级分段" -
设置多语言支持参数(中文需特别配置)
2. 混合检索配置
在Dify工作流中设置:
retrieval_strategy:
-vector_search:
model:jina-embeddings-v2-base-zh
top_k:8
-full_text:
analyzer:ik_max_word
rerank:
model:bge-reranker-large
score_threshold:0.35
该配置融合语义检索与关键词匹配,经测试可使表格类数据召回率提升
四、准确率提升核心策略
1. 文档解析优化
-
布局感知技术:RAGFlow通过CV算法识别PDF中的表格位置,避免传统OCR的错位问题(测试显示扫描件表格解析完整度提升62%) -
智能分块算法: -
中文使用"。"分段(比换行符准确率提高28%) -
表格采用"标题+单元格"关联存储 -
图片自动生成AltText并建立跨模态索引
-
2. 检索增强机制
-
多路召回策略: -
向量检索:捕获语义相似性 -
全文检索:确保关键词匹配 -
图召回:基于文档内部关联扩展
-
-
动态重排序:使用BGE模型对Top50结果重排,消除"语义漂移"现象
3. 工作流优化
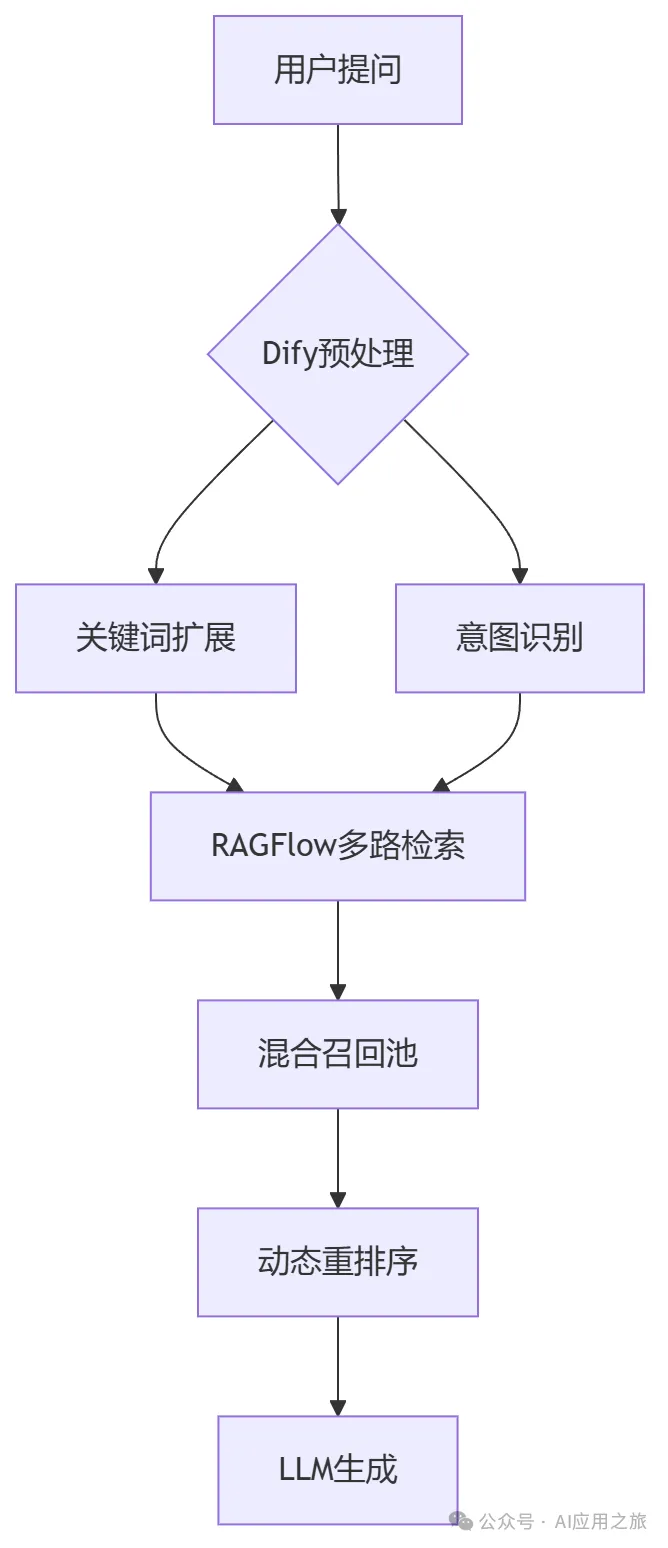
五、效果验证与调优
1. 案例对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
2. 参数调优指南
-
TopK动态调整:根据文档平均长度设置(建议6-12区间) -
Score阈值:从0.3开始测试,每0.05为步长调整 -
分段重叠率:设置10-15%避免信息割裂
六、准确率提升原理总结
-
深度文档理解:RAGFlow的布局解析算法突破传统NLP工具的限制,特别在处理扫描件、复杂表格时展现优势 -
混合检索机制:结合Dify的灵活工作流编排,实现"关键词+语义+关联"的三维匹配 -
动态优化策略:基于重排序模型和参数自适应的持续优化闭环 -
本地化部署:消除API传输损耗,确保原始数据安全性
操作文档参考:
-
RAGFlow官方部署指南 -
Dify外部知识库配置手册 -
混合检索参数优化白皮书