大模型(LLMs)是一种人工智能模型,旨在理解和生成人类语言。
它们通过在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。这些模型通常基于深度学习架构,如转换器,这使它们在各种自然语言处理任务上表现出令人印象深刻的能力。
大模型领域在国内外都取得了显著的成就,各个国家和地区的企业、机构以及学术界都在积极投入资源和努力,推动大模型技术的发展。
比如,在国外,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。
在国内,截至2023年8月31日,多家大模型企业和机构正式宣布其服务已经上线,并向全社会开放。目前,百度、智谱、百川、字节、商汤、中科院(紫东太初)等8个企业和机构的大模型名列第一批备案名单,它们可以正式上线并向公众提供服务。
为了让大家能更加直观的看到大模型领域的发展,我们整理了国内外顶尖的大模型,提供给大家参考和使用。
国外大模型汇总
Open AI
ChatGPT
ChatGPT是由GPT-3语言模型驱动的开源聊天机器人。它能够与用户进行自然语言对话交流。ChatGPT经过广泛的主题训练,可以帮助回答问题、提供信息和生成创意内容等各种任务。它被设计成友好和乐于助人的,可以适应不同的对话风格和语境。通过ChatGPT,您可以在最新新闻、时事、爱好和个人兴趣等各种话题上进行有趣而富有信息的对话。
论文:
Language Models are Few-Shot Learners
www.aminer.cn/pub/5ed0e04291e011915d9e43ee

GPT-4
2023年3月,OpenAI 发布了多模态预训练大模型 GPT-4,能接受图像和文本输入,再输出正确的文本回复。实验表明,GPT-4 在各种专业测试和学术基准上的表现与人类水平相当。例如,它通过了模拟律师考试,且分数在应试者的前 10% 左右;相比之下,GPT-3.5 的得分在倒数 10% 左右。
论文:
GPT-4 Technical Report
www.aminer.cn/pub/641130e378d68457a4a2986f
LaMDA
LaMDA是一系列专门用于对话的基于Transformer的模型。这些模型拥有多达1370亿个参数,并使用1.56万亿个公开对话数据进行训练。LaMDA可以在各种话题上进行自由流畅的对话。与传统的聊天机器人不同,它不受预定义路径的限制,可以根据对话的方向进行自适应调整。
论文:
LaMDA: Language Models for Dialog Applications
www.aminer.cn/pub/61ea249b5244ab9dcbabc7ac
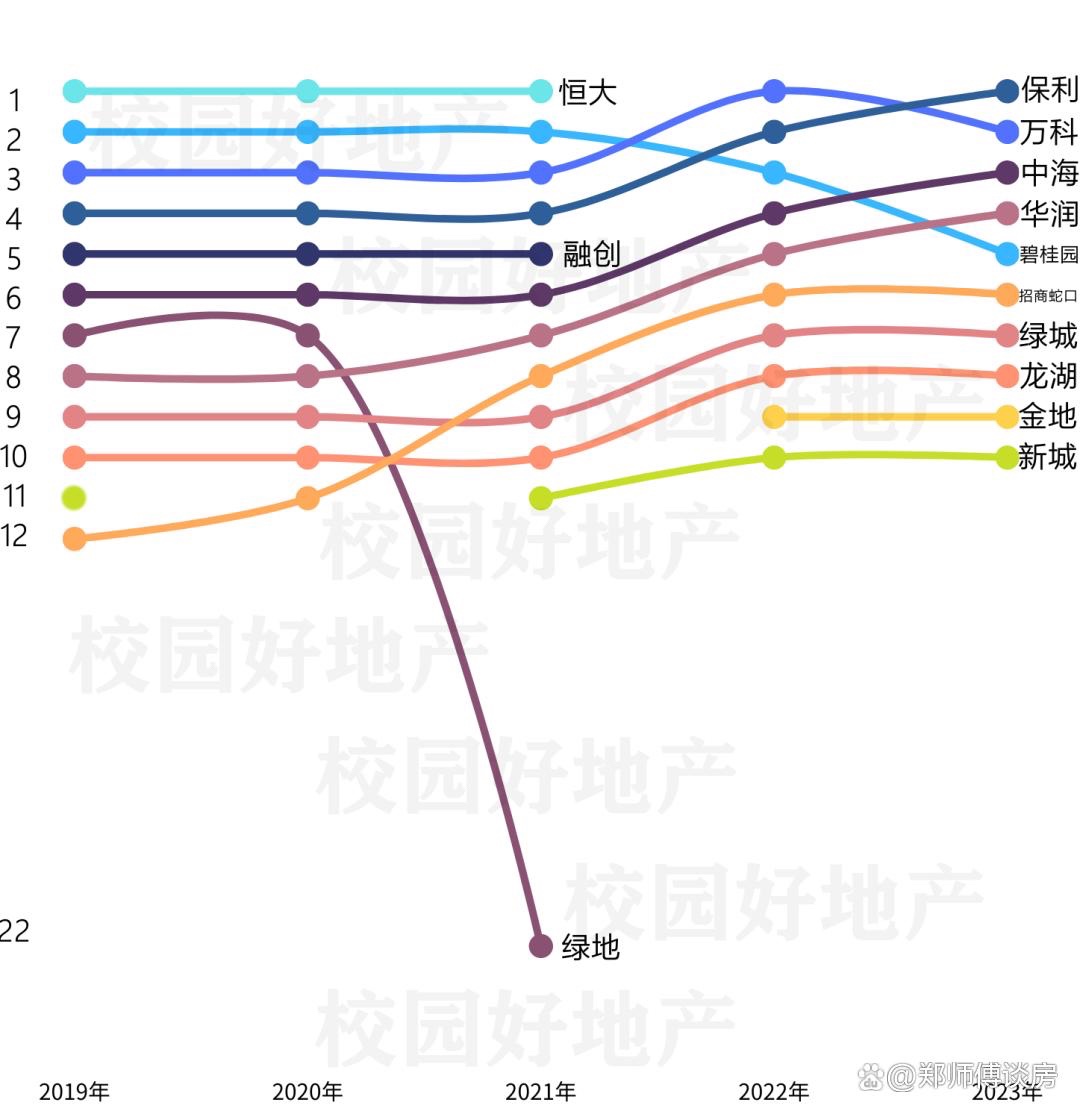
PaLM
PaLM是一个具有5400亿个参数的语言模型,能够处理各种任务,包括复杂的学习和推理。它在语言和推理测试中可以胜过最先进的语言模型和人类。PaLM系统采用了少样本学习的方法,可以从少量的数据中泛化,近似模拟人类学习和应用知识来解决新问题的方式。
论文:
undefined - AMiner
www.aminer.cn/pub/624d050e5aee126c0f4a7920
mT5
多语言T5(mT5)是一个由130亿个参数组成的文本到文本的Transformer模型。它是在mC4语料库上进行训练的,涵盖了101种语言,如阿姆哈拉语、巴斯克语、科萨语、祖鲁语等。mT5能够在许多跨语言自然语言处理任务上达到最先进的性能水平。
论文:
mT5: A massively multilingual pre-trained text-to-text transformer
www.aminer.cn/pub/5f92ba5191e011edb3573ba5

Deepmind
Gopher
DeepMind的语言模型Gopher在回答关于科学、人文等专业主题的问题等任务上比现有的大型语言模型更准确,而在逻辑推理和数学等其他任务上与它们相当。Gopher拥有2800亿个参数可供调整,使其比OpenAI的GPT-3更大,后者只有1750亿个参数。
论文:
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
www.aminer.cn/pub/61b2c0246750f848a14300ff
Chinchilla
Chinchilla使用与Gopher相同的计算预算,但只有700亿个参数和四倍的数据。在许多下游评估任务中,它胜过了Gopher、GPT-3、Jurassic-1和Megatron-Turing NLG等模型。它在微调和推理方面使用的计算资源明显较少,极大地促进了下游应用的使用。
论文:
An empirical analysis of compute-optimal large language model training
www.aminer.cn/pub/63a413f690e50fcafd6d190a

Sparrow
Sparrow是由DeepMind开发的聊天机器人,旨在正确回答用户的问题,同时减少不安全和不适当回答的风险。Sparrow的动机是解决语言模型产生不正确、带偏见或潜在有害输出的问题。Sparrow通过使用人类判断进行训练,使其比基线预训练语言模型更有帮助、更正确和更无害。
论文:
Improving alignment of dialogue agents via targeted human judgements
www.aminer.cn/pub/63365e7c90e50fcafd1a2bdd
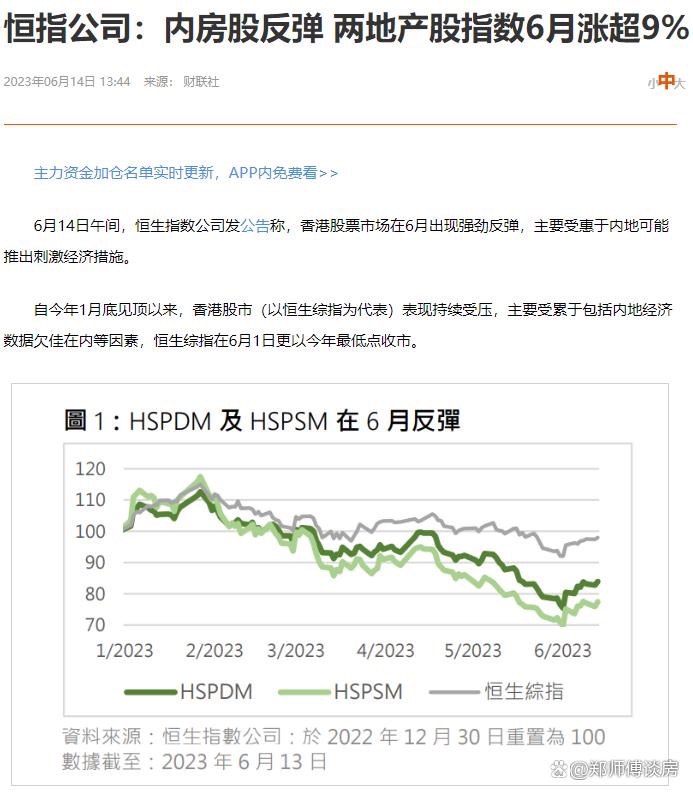
Anthropic
Claude
Claude是一个由先进的自然语言处理驱动的基于AI的对话助手。它的目标是成为有益、无害和诚实的助手。它使用一种称为Constitutional AI的技术进行训练。在训练过程中,通过模型自我监督和其他AI安全方法,对其进行限制和奖励,以展现之前提到的行为特征。
论文:
Constitutional AI: Harmlessness from AI Feedback
www.aminer.cn/pub/63a1750c90e50fcafd1f38d7

Meta
OPT-IML
OPT-IML是基于Meta的OPT模型的预训练语言模型,拥有1750亿个参数。OPT-IML经过微调,以在自然语言任务(如问答、文本摘要和翻译)中获得更好的性能,使用了约2000个自然语言任务进行训练。它在训练过程中更高效,并且比OpenAI的GPT-3具有更低的CO₂排放量。
论文:
OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
www.aminer.cn/pub/63a910a290e50fcafd2a84fd

BlenderBot-3
BlenderBot 3是一个可以与人交互并接收反馈以提高对话能力的对话代理。BlenderBot 3是基于Meta AI公开提供的OPT-175B语言模型构建的,该模型的规模大约是其前身BlenderBot 2的58倍。该模型融合了人格、共情和知识等对话技能,并通过利用长期记忆和搜索互联网来进行有意义的对话。
论文:
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
www.aminer.cn/pub/62f07ec290e50fcafde5ac5e
Llama
LLaMA是拥有7B到65B参数的基础语言模型。作者在数万亿令牌上进行了训练,并展示了使用公开可用数据集训练最先进的模型是可能的,而不必依赖于专有和不可访问的数据集。其中,LLaMA-13B在大多数基准测试中优于GPT-3(175B),而LLaMA-65B与最佳模型,Chinchilla-70B和PaLM-540B,具有竞争力。
论文:
LLaMA: Open and Efficient Foundation Language Models
www.aminer.cn/pub/63fd715e90e50fcafd14767c/llama-open-and-efficient-foundation-language-models
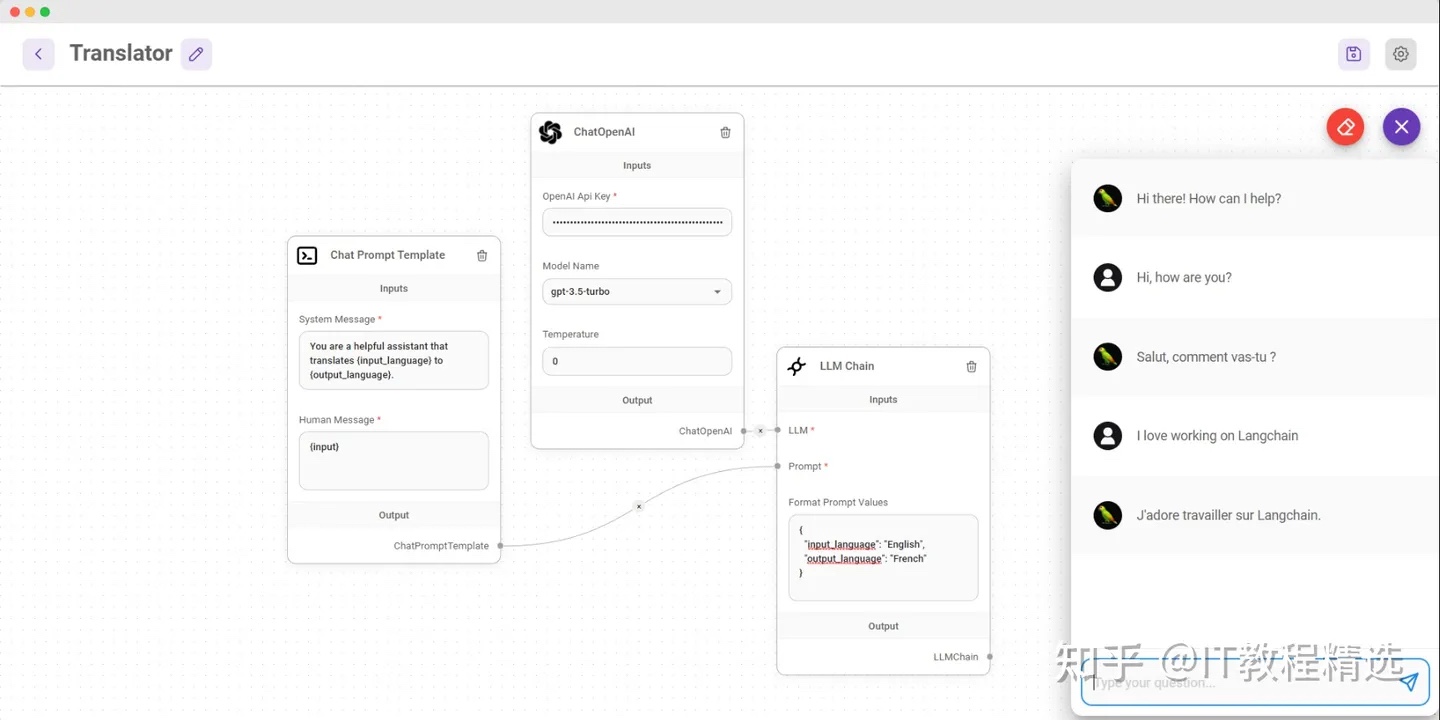
Llama2
Llama 2,一个包括从 70 亿到 700 亿个参数的预训练和优化的大型语言模型 (LLM) 集合。其中的 Llama 2-Chat 是针对对话场景优化的 LLM,并在大多数测试的基准上表现优于开源聊天模型。
论文:
Llama 2: Open Foundation and Fine-Tuned Chat Models - AMiner
www.aminer.cn/pub/64b758dd1a5852438b7976ff/llama-open-foundation-and-fine-tuned-chat-models
AI21 Labs
Jurassic
Jurassic-1是AI21 Labs推出的开发者平台,为构建应用程序和服务提供最先进的语言模型。它提供了两个模型,其中包括Jumbo版本,是迄今为止发布的最大、最复杂的通用语言模型。这些模型非常灵活,能够生成类似于人类的文本,并解决诸如问答和文本分类等复杂任务。
论文:
undefined - AMiner
www.aminer.cn/pub/62620f1c5aee126c0f686cf5
NVIDIA
Megatron-Turing NLG
Megatron-Turing自然语言生成(MT-NLG)模型是一个基于Transformer的语言模型,拥有5300亿个参数,使其成为同类模型中最大且最强大的模型。它在零、一和少样本设置中超越了之前的最先进模型,并在完成预测、常识推理、阅读理解、自然语言推理和词义消歧等自然语言任务中展现了无与伦比的准确性。
论文:
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
www.aminer.cn/pub/61f753205aee126c0f9c2149
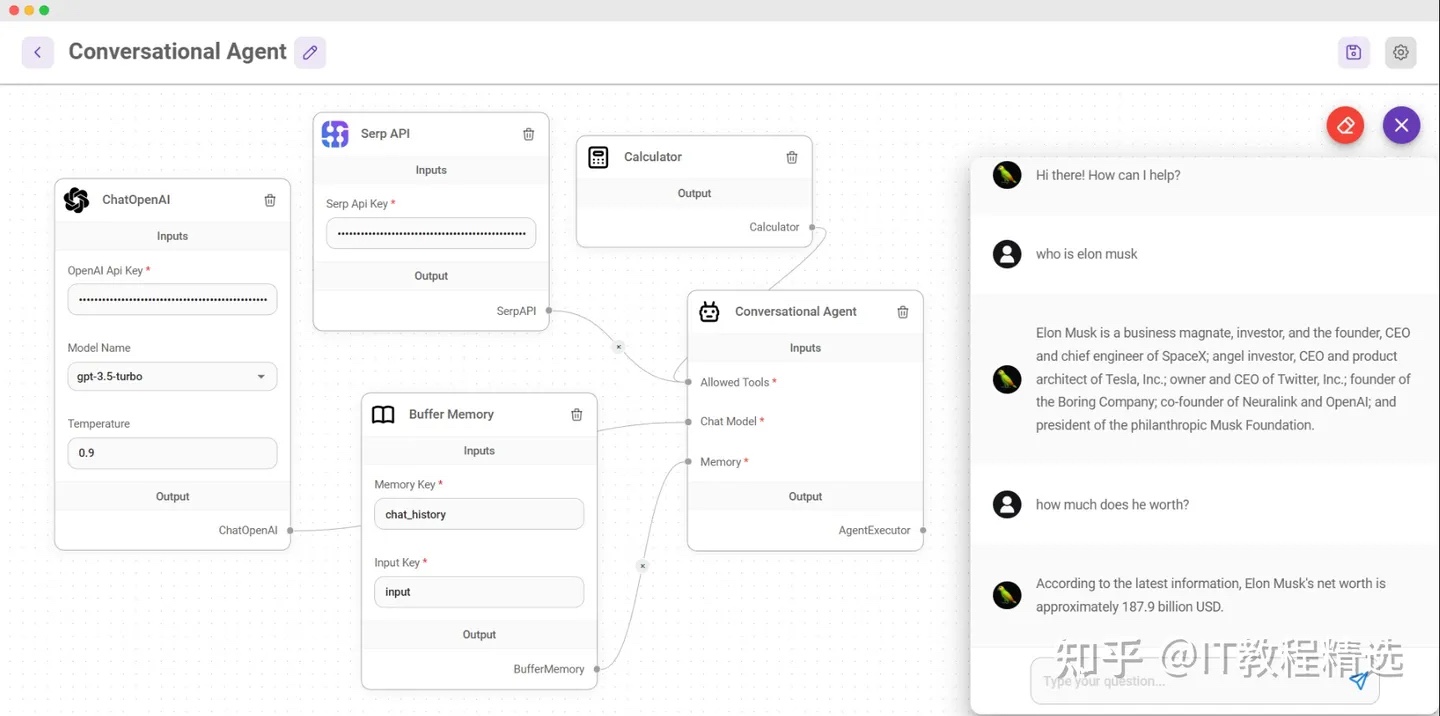
国内大模型汇总
百度
Ernie 3.0 Titan
由百度和鹏程实验室联合发布,它有 260B 个参数,擅长自然语言理解和生成。它在海量非结构化数据上进行了训练,并在机器阅读理解、文本分类和语义相似性等 60 多项 NLP 任务中取得了一流的成绩。此外,泰坦还在 30 项少拍和零拍基准测试中表现出色,这表明它有能力利用少量标记数据在各种下游任务中进行泛化。
论文:
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
www.aminer.cn/pub/61c53a815244ab9dcbcaf3b5
Ernie Bot
于 3 月份完成 "Ernie Bot "项目的内部测试。Ernie Bot 是一种人工智能语言模型,类似于 OpenAI 的 ChatGPT,能够进行语言理解、语言生成和文本到图像的生成。这项技术是全球开发生成式人工智能竞赛的一部分。
论文:
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
www.aminer.cn/pub/60e441e0dfae54001623c105
智谱AI
GLM
一个基于自回归填空的通用预训练框架,通过在一个统一的框架中同时学习双向和单向的注意力机制,模型在预训练阶段同时学习到了上下文表示和自回归生成。在针对下游任务的微调阶段,通过完形填空的形式统一了不同类型的下游任务,从而实现了针对所有自然语言处理任务通用的预训练模型。
论文:
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
www.aminer.cn/pub/622819cdd18a2b26c7ab496a
GLM-130B
GLM-130B 是一个开源开放的双语(中文和英文)双向稠密模型,拥有 1300 亿参数,模型架构采用通用语言模型(GLM)。它旨在支持在一台 A100(40G * 8)或 V100(32G * 8)服务器上对千亿规模参数的模型进行推理。在 INT4 量化方案下,GLM-130B 可以几乎不损失模型性能的情况下在 RTX 3090(24G * 4)或 GTX 1080 Ti(11G * 8)服务器上进行高效推理。
论文:
GLM-130B: An Open Bilingual Pre-trained Model
www.aminer.cn/pub/633e476890e50fcafde59595
ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。该模型基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的ChatGLM-6B 虽然规模不及千亿模型,但大大降低了推理成本,提升了效率,并且已经能生成相当符合人类偏好的回答。
华为
PanGu-Alpha
华为开发了一种与 OpenAI 的 GPT-3 相当的中文模型,称为 PanGu-Alpha。该模型基于 1.1 TB 的中文资源,包括书籍、新闻、社交媒体和网页,包含超过 2000 亿个参数,比 GPT-3 多 2500 万个。PanGu-Alpha 能高效完成各种语言任务,如文本摘要、问题解答和对话生成。
论文:
undefined - AMiner
www.aminer.cn/pub/6087f2ff91e011e25a316d31
阿里
M6
2021年6月,阿里巴巴联合清华大学发表了一项新研究,提出了参数规模达到1000亿的中文预训练模型 M6,是当时最大规模的中文多模态预训练模型。M6的应用适用于广泛的任务,包括产品描述生成、视觉问答、问答、中国诗歌生成等,实验结果表明M6的表现优于一系列强大的基准。并且,研究人员还专门设计了文本引导的图像生成任务,并证明经过微调的 M6 可以创建具有高分辨率和丰富细节的高质量图像。
论文:
M6: Multi-Modality-to-Multi-Modality Multitask Mega-transformer for Unified Pretraining
www.aminer.cn/pub/60c320b19e795e9243fd1672

通义千问
2023年4月,阿里发布了「通义千问」,一个超大规模的语言模型,具备多轮对话、文案创作、逻辑推理、多模态理解、多语言支持等功能。
而就在前几天,阿里再次推出以通义千问70亿参数模型Qwen-7B为基座语言模型:Qwen-VL,支持图文输入,具备多模态信息理解能力。除了具备基本的图文识别、描述、问答及对话能力之外,还新增了视觉定位、图像中文字理解等能力。
论文:
Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities
www.aminer.cn/pub/64e826d63fda6d7f06c3150c

商汤
日日新
2023年4 ,商汤推出大模型 “日日新”,包括自然语言处理模型 “商量”、文生图模型 “秒画” 和数字人视频生成平台 “如影” 等。这也是继百度文心一言、阿里通义千问之后,又一国内大厂的类 ChatGPT 产品。
最近,商汤大模型团队也提出了文生图大模型RAPHAEL,详细请看论文。
论文:
RAPHAEL: Text-to-Image Generation via Large Mixture of Diffusion Paths
www.aminer.cn/pub/647572e0d68f896efa7b79ab

快手
KwaiYiiMath
一种增强 KwaiYiiBase1 数学推理能力的技术报告。通过应用监督微调(SFT)和基于人类反馈的强化学习(RLHF),KwaiYiiMath 在英语和中文数学任务上都有所提升。同时,作者还构建了一个小规模的中国小学数学测试集(简称 KMath),包含 188 个例子,用于评估模型生成的解题过程的正确性。实证研究表明,与类似大小的模型相比,KwaiYiiMath 在 GSM8k、CMath 和 KMath 上分别实现了最先进的(SOTA)性能。
论文:
KwaiYiiMath: Technical Report
www.aminer.cn/pub/65275731939a5f4082a450ee/kwaiyiimath-technical-report?f=wb

除以上模型之外,国内模型还有百川智能模型、抖音的云雀大模型、中科院 “紫东太初”模型、上海人工智能实验室的书生大模型、MiniMax 的 ABAB 大模型等。
在2023年,国内外不断涌现出新的模型,我们目睹了大模型的爆炸式增长。随着大模型的不断演进和优化,我们可以期待它们在自然语言处理、图像识别、语音识别等领域的性能不断提升,甚至超越人类的水平。
这将推动人工智能技术在各个行业的广泛应用,从医疗到金融,从交通到教育,大模型将成为智能设备和服务的核心。我们的生活将变得更加智能化、便捷化和个性化。
当然,大模型的未来发展也面临一些挑战和问题,如隐私和安全性等。然而,随着技术的进步和应用的拓展,这些问题将逐步得到解决和克服。
总的来说,一切交给时间来证明!
如何使用ChatPaper?
使用ChatPaper的方法很简单,打开AMiner首页,从页面顶部导航栏或者右下角便可进入ChatPaper页面。